
Technology
Semantic Web - Love it and hate it
Wednesday April 6, 2016
I have chosen to follow the Data Science course as part of my Computer Science master program. This course consists of a number of topics which can be chosen. One of these topics was “Semantic Web”. After a short presentation by the teacher the topic seemed not only interesting from a technological point of view, but it also looked like a fantastic thing to have. However, as with many upcoming technologies, the practical side of it turned out to be difficult at least.
So, what is this “Semantic Web”?
As usual, let’s start off with a quote from Wikipedia:
The Semantic Web is an extension of the Web through standards by the World Wide Web Consortium (W3C). The standards promote common data formats and exchange protocols on the Web, most fundamentally the Resource Description Framework (RDF).
According to the W3C, “The Semantic Web provides a common framework that allows data to be shared and reused across application, enterprise, and community boundaries”. The term was coined by Tim Berners-Lee for a web of data that can be processed by machines. While its critics have questioned its feasibility, proponents argue that applications in industry, biology and human sciences research have already proven the validity of the original concept.
Wikipedia — https://en.wikipedia.org/wiki/Semantic_Web
This definition is not very usable without some background knowledge. Instead of giving you the background knowledge (or letting you search for it yourself), I’ll just give the gist of what the Semantic Web is.
The Semantic Web is a collection of web standards (using technologies like HTTP, XML) allowing for information to be represented in a machine understandable way. This information can be linked to information from other sources all over the internet. When converted to an appropriate format the data can be queried.
Data representation
The data in the Semantic Web is essentially a graph consisting of vertices (which either have an identifier or contain ‘simple’ data) and edges (which are properties of these objects). A class or data type is not defined by its properties but by its restrictions. By default a class contains all vertices, this can be limited by placing different requirements on properties (edges to other vertices) like expected types, values or cardinality. The data can exist without a schema, but the schema is the part which gives meaning to the data.
Since computers have to understand the data it must adhere to a certain format. Ontologies serve as a schema. An ontology is basically a schema for a graph. You can specify classes in terms of their edges. This allows for inference, for instance, when two different classes specify exactly the same edges, they must be equal. If you like to read more (and there is a lot more of it), check out OWL.
An example of a simple class in OWL:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
<rdf:RDF>
<owl:Class rdf:ID="Person">
<rdf:subClassOf>
<owl:restriction>
<owl:onProperty rdf:resource="#gender"/>
<owl:maxCardinality>1</owl:maxCardinality>
</owl:restriction>
</rdf:subClassOf>
</owl:Class>
<owl:Class rdf:ID="Male">
<rdf:subClassOf rdf:resource="#Person"/>
<rdf:subClassOf>
<owl:restriction>
<owl:onProperty rdf:resource="#gender"/>
<owl:hasValue>M</owl:hasValue>
</owl:restriction>
</rdf:subClassOf>
</owl:Class>
<owl:DatatypeProperty rdf:ID="gender">
<rdfs:domain rdf:resource="#Person"/>
<rdfs:range rdf:resource="xsd:string"/>
</owl:DatatypeProperty>
</rdf:RDF>
In the example I defined a class Person with a property gender (which is expected to be either M or F, which is not explicitly defined here).
A Person instance is of type Person because of the gender property.
However, it is also of type Male if the value of gender is M, as defined by the Male class.
The data is added by specifying class instances by adding edges to other class instances. This is not so complicated, so that’s nice.
1
2
3
4
5
6
<rdf:RDF>
<Person rdf:ID="John_Doe_1">
<gender>M</gender>
</Person>
<Male rdf:ID="John_Doe_2"/>
</rdf:RDF>
(You might have noticed that both objects are equal, apart from their ID.)
So far so good.
In practice
While the theory sounds nice, it becomes clear that this is not a technology which has fully developed when you start using it.
A number of problems I ran into:
- RDF (and therefore OWL) is not user friendly. It feels like a mess. Which I’m sure it is not. But it feels that way. (Also, IntelliJ does not understand it.)
- There are multiple dialects (DAML and multiple versions of OWL) to specify ontologies in. Which are not compatible with eachother.
- Tooling supports only a small number of versions of the description language (DAML/OWL).
- There are multiple (about a dozen) representations for the same data (including XML/RDF and triples), some tools prefer XML, some tools something else.
- Apache Jena is very good at giving error messages. However, it is not very good at giving descriptive error messages (or anything other than “Something went wrong”).
- There is not much documentation, and the documentation that is there requires in-depth knowledge of the field. Also, if you finally found a good resource, it probably is for a different version than you were looking for.
In conclusion, the Semantic Web part of the Data Science course turned out to be mostly trial and error.
When it finally comes together
At some point you are ready to give up. I certainly was. But just push through the pain and continue - only a moment later you might finally find another solution which works. Then you understand what the fuss is about.
The Semantic Web is awesome.
The figure below shows a simple graph containing information about concert dates and ticket prices. This is data a concert venue has. DBpedia, a public resource containing data crawled from Wikipedia, has information about an artist.
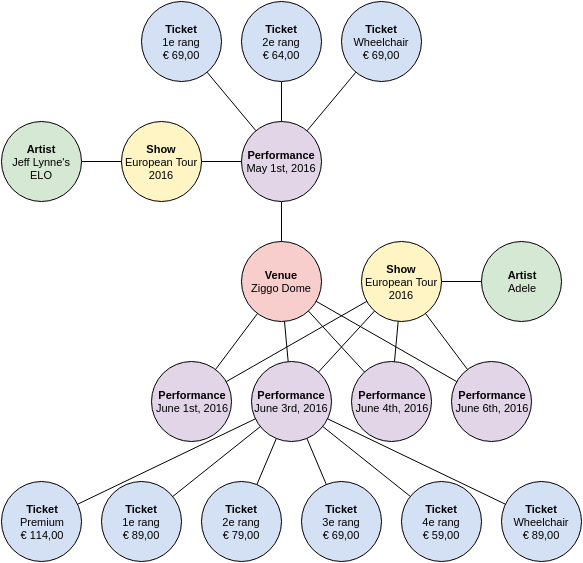
In our data we can specify that our Artist node for Adele is equal to her DBpedia article. When querying the data (using SPARQL) we can easily obtain the data from DBpedia given our own data. The reverse is also possible.
If you are still reading (I forgive you if you’re not) you probably think “Why?”. This is the answer:
- If you type ‘Adele’ into Google, it shows data from DBpedia. If such a standard existed, Google will be able to display upcoming Adele concerts near you.
- If you are buying Adele tickets and you are in doubt, the website might provide information about Adele gathered from open data.
- If Adele tickets are sold out, the website might give you recommendations of other artists based on the open data.
The key word, as you might have noticed, is “standard”. In your queries you most likely need to know the property/edge names to find the data you want. This means you do need to know this in advance. I still have to see whether a global standard will evolve from user initiatives like DBpedia.
The usual question is “love it or hate it”. I honestly cannot give a straight answer. Even with a gun to my face I will need words like ‘but’ and ‘however’ to answer that question.
I think I love it and hate it.
Read more
Comments?
Drop me an e-mail at janjelle@jjkester.nl.